PostgreSQL HA setup using ansible
A declarative approach on the most popular automation tool.
Introduction
Quite early on working with automation tools like ansible, you will realise the need that they really satisfy. Yes, they will help you to repeatedly configure a system, fast, without errors -like a script will do- and sure, they will describe that configuration in a more humanly readable yaml form. But the real power with these tools is that they give you the ability to be declarative on configurations, installations, topologies that you deliver in the end.
Think of an installation that includes multiple nodes, multiple layers of services, with a heavy integration layer. Add some availability and security policies. Also, keep in mind that every system need to be maintainable, expandable on demand and recoverable during unpredictable failures. Before configuration management tools, all these, required manual changes to the system from multiple specialists during time. After some time, the system nearly reminds nothing about the initially delivered and there is no way to deliver the mature system again.
This phenomenon which described as “configuration drift”, is the problem that all these configuration management tools try to resolve.
Is using configuration management tools makes you declarative? Not necessarily. For example, you can use the “command” module of ansible in a way that the tool connot recognize if your command made a change to the remote system or not. In general the configuration management / automation tool need to be aware of changes made to the system.
And this is the article’s purpose: Demonstrate the need and respond with a fully functional example.
What you will learn
As you continue reading you will see some things that are not so intuitive working with ansible:
- How grouping (or tagging on cloud systems) in inventory helps you describe your topology
- How you can use system's environment variables as ansible variables (useful for passwords or other sensitive values)
- How you can use “handlers”to execute tasks, only if another task made a change
- How you can access variables (or “facts”) of a host, on other hosts in order to declare integration between them
The system to deliver
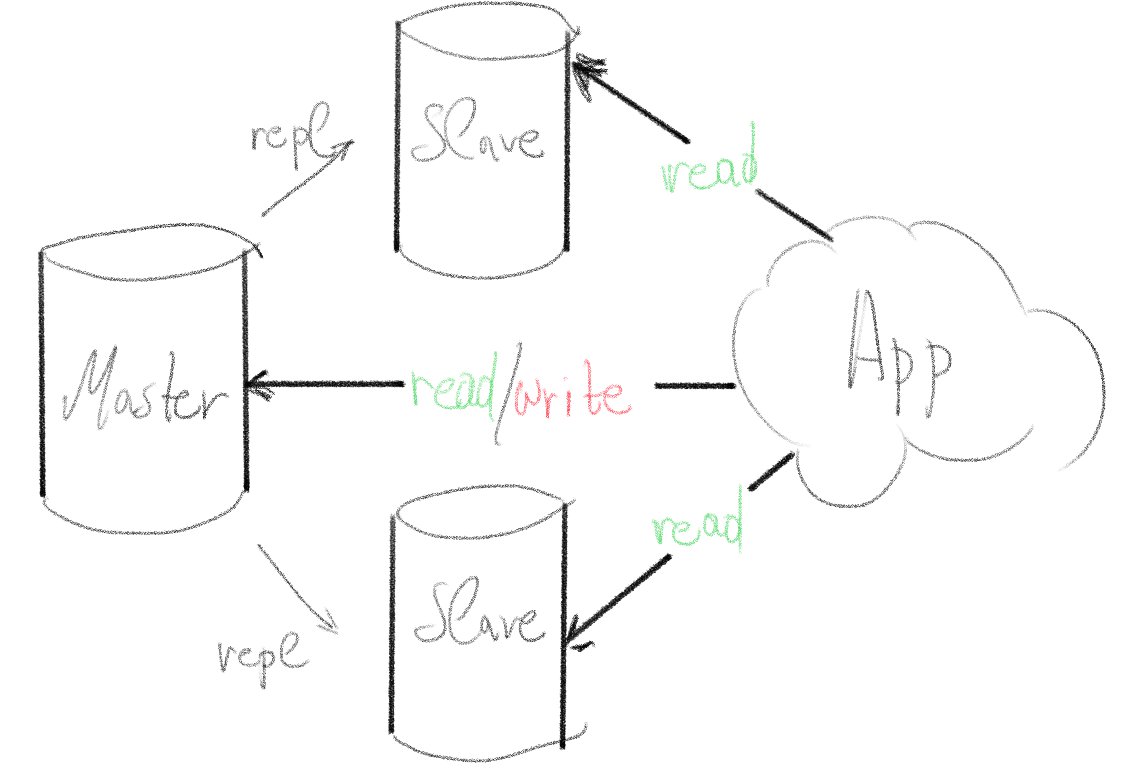
We will create a master PostgreSQL database with two hot replicas. By "hot" we mean that the data is replicated live only one-way. From master to slave databases. We can use the master database to read/write data but the slaves will remain up at anytime only for reading (select) data.
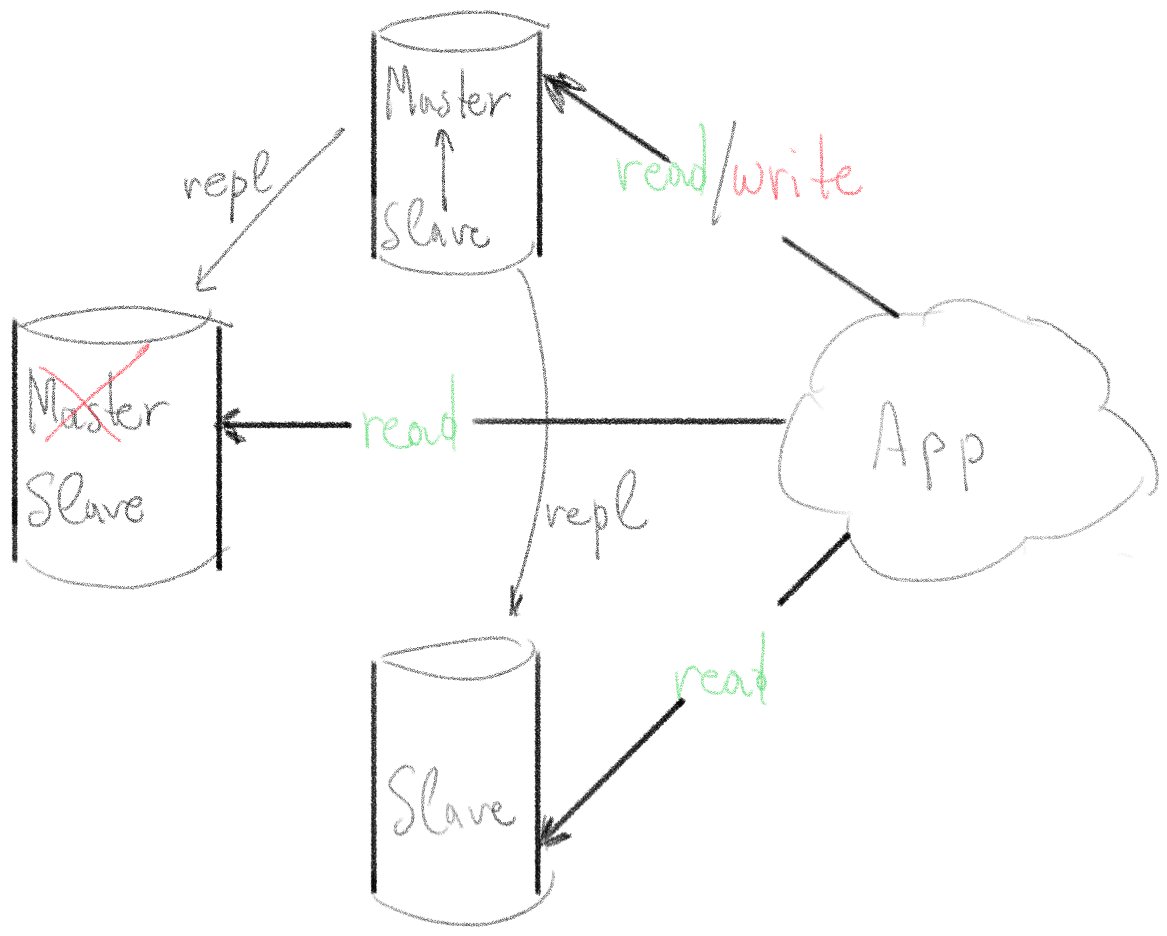
We will not set up automatic fail over for the master database (for now). Instead, we will write our ansible playbook with the ability to intentionally promote a server from slave to master (without data loss) and start replication data from the new "master" to the other 2 servers.
Software Versions
Note that version 12 of PostgreSQL has deprecated recovery.conf file for standby servers. If your are planning to use older versions than 12, you need to make some changes to the playbooks.
- Ansible 2.8.5 (python version = 3.6.8)
- PostgreSQL V12.0
- CentOS 8
![]()
![]()
![]()
Inventory
hosts
pgdb1
pgdb2
pgdb3
[db_master]
pgdb1
[db_slaves]
pgdb2
pgdb3
The inventory above implies that we will create some tasks for all the database servers, some tasks for the master database only and some tasks for the slaves. Of course all hostnames are resolvable by DNS and our public ssh key is on privileged user 'ansible' on every host.
But let's go straight to our playbook.
The playbook
pg_setup.yml
---
- hosts: db_hosts
vars:
repl_user: replusr
repl_passwd: "{{ lookup('env', 'PG_REPL_PASSWD') }}"
remote_user: ansible
become: True
tasks:
- name: Check if database is standing by
stat:
path: '/var/lib/pgsql/12/data/standby.signal'
register: standby_status
- name: Execute prequisites on all hosts
import_tasks: pg_prequisites.yml
when: inventory_hostname in groups['db_hosts']
- name: Configure master node
import_tasks: pg_conf_master.yml
vars:
standby_status: "{{ standby_status }}"
when: inventory_hostname in groups['db_master']
become_user: postgres
- name: Configure slave nodes
import_tasks: pg_conf_slave.yml
when: inventory_hostname in groups['db_slaves']
become_user: postgres
vars:
master_host: "{{ groups.db_master[0] }}"
handlers:
- name: Restart Linux server
reboot:
- name: Restart database
systemd:
state: restarted
name: postgresql-12
Our playbook will need a username (repl_user) for slave databases to connect on the master and start replicating data. It will also need a password for this user but we gave this as environment variable because we do not want our playbook to contain sensitive data.
So, in order to run we need:
... and then execute with:
Notes:
- We do not have all the task sequence here. Instead, we are using "import_tasks" module to execute pg_prequisites.yml, pg_conf_master.yml and pg_conf_slave.yml files that will folllow.
- We built our playbook in order to survive changes in inventory file. For example we can add a new slave or move the master node to "db_slaves" group and "promote" a slave to master. All we need to do is make the changes to inventory and run the same playbook again.
- Because of the 2. we need ansible to know if a node has PostgreSQL installed and if was master or slave before execution. So we are feeding pg_conf_master.yml and pg_conf_slave.yml with "stabdby_status" and "master_host" variables respectively. The tasks will act slightly differently depending on those variables as will see.
The tasks
pg_prequisites.yml
---
- name: Install PostgreSQL 12 packages
dnf:
name:
- postgresql12
- postgresql12-server
- postgresql12-contrib
- python3-psycopg2
state: present
- name: Enable database service on boot
systemd:
name: postgresql-12
enabled: yes
- name: Open postgresql service on firewall
firewalld:
source: "{{ hostvars[item]['ansible_ens3']['ipv4']['address'] }}"
zone: internal
state: enabled
service: postgresql
permanent: yes
with_items: "{{ groups['db_hosts'] }}"
- name: Reload firewalld
systemd:
state: reloaded
name: firewalld
Notes:
- The "python3-psycopg2" is required for the pg_* ansible modules to work.
- The firewall will remain active, so we need to permit connections on postgresql service only from the cluster members. Check how we are looping over magic variable "groups" in order to feed the task "Open postgresql service on firewall" with the ipv4 addresses.
pg_conf_master.yml
---
- name: Check if database is already initialized
stat:
path: '/var/lib/pgsql/12/data/PG_VERSION'
register: init_status
- name: Initialize the master database
shell: "/usr/pgsql-12/bin/postgresql-12-setup initdb"
when: init_status.stat.exists == False
become_user: root
- name: Promote slave database to master
shell: "/usr/pgsql-12/bin/pg_ctl promote -D /var/lib/pgsql/12/data"
when: init_status.stat.exists == True and standby_status.stat.exists == True
- name: Start database
systemd:
state: started
name: postgresql-12
become_user: root
- name: Create replication user, set MD5-hashed password, grant privs
postgresql_user:
name: replusr
password: "{{ 'md5' + ((repl_passwd + repl_user) | hash('md5')) }}"
role_attr_flags: REPLICATION
priv: ALL
db: postgres
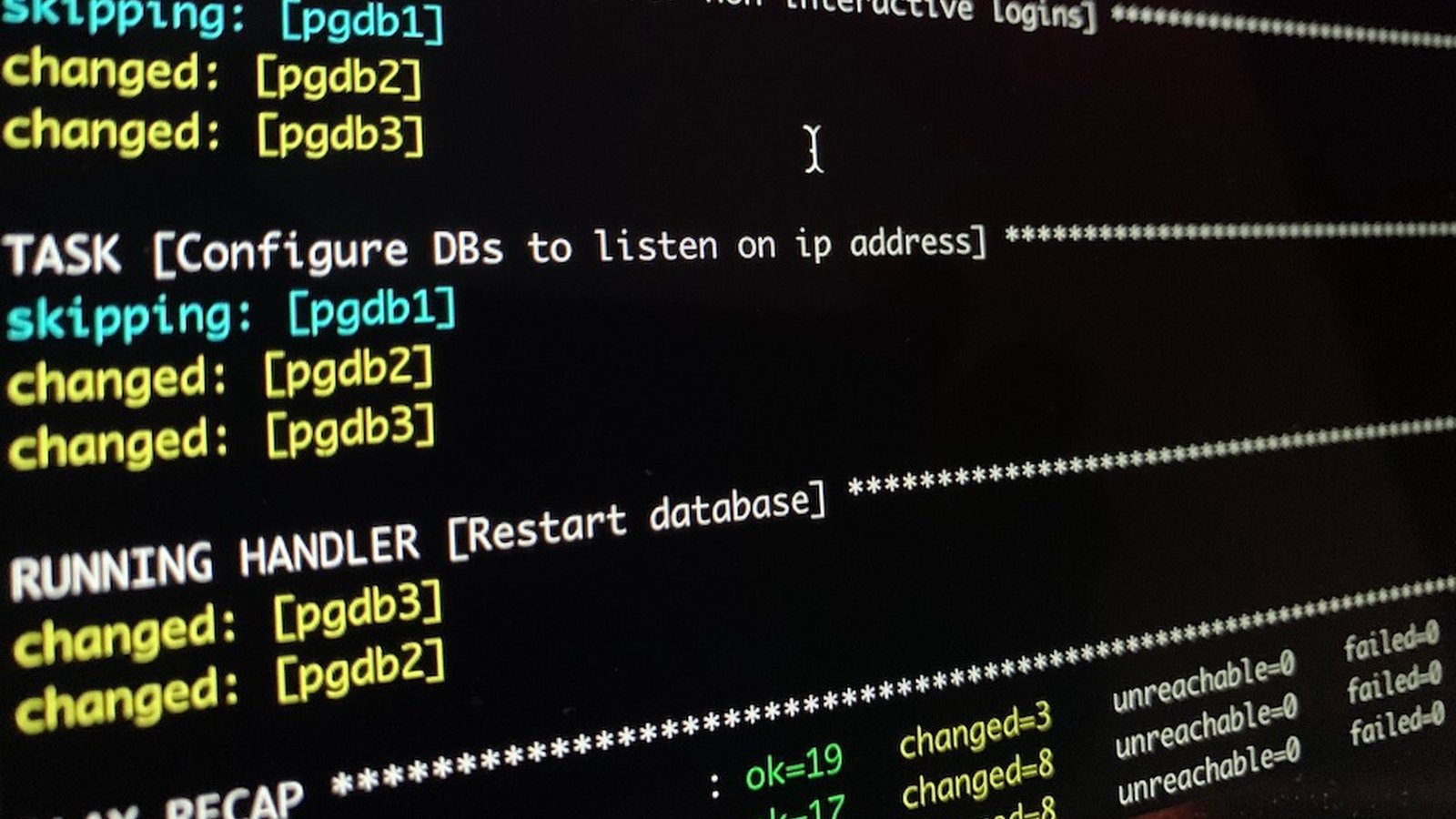
- name: Configure DBs to listen on ip address
postgresql_set:
name: listen_addresses
value: 'localhost,{{ ansible_ens3.ipv4.address }}'
- name: Configure wal_level parameter
postgresql_set:
name: wal_level
value: 'replica'
- name: Configure wal_log_hints parameter
postgresql_set:
name: wal_log_hints
value: 'on'
- name: Configure max_wal_senders parameter
postgresql_set:
name: max_wal_senders
value: '8'
- name: Configure wal_keep_segments parameter
postgresql_set:
name: wal_keep_segments
value: '8'
- name: Configure hot_standby parameter
postgresql_set:
name: hot_standby
value: 'on'
- name: Enable replication user to login
blockinfile:
path: /var/lib/pgsql/12/data/pg_hba.conf
block: |
{% for host in groups['db_hosts'] %}
host replication replusr {{ hostvars[host]['ansible_facts']['ens3']['ipv4']['address'] }}/32 md5
{% endfor %}
- name: Restart database
systemd:
state: restarted
name: postgresql-12
become_user: root
when: standby_status.stat.exists == False
Notes:
- We depend on the existence of "/var/lib/pgsql/12/data/PG_VERSION" file to determine if the database is installed and initialized.
- On task "Create replication user, set MD5-hashed password, grant privs" you can see how you can calculate the md5 hash of a password inside a playbook.
- On task "Enable replication user to login" you can see how you can loop over "groups" magic variable generating one line per host in pg_hba.conf file.
pg_conf_slave.yml
---
- name: pgpass for non interactive logins to the other node
blockinfile:
path: /var/lib/pgsql/.pgpass
create: yes
mode: 0600
block: |
# hostname:port:database:username:password
{% for host in groups['db_hosts'] %}
{{ hostvars[host]['inventory_hostname'] + ':5432:replication:' + repl_user + ':' + repl_passwd}}
{% endfor %}
- name: Stop database
systemd:
state: stopped
name: postgresql-12
become_user: root
- name: Remove data
file:
state: absent
path: "/var/lib/pgsql/12/data/"
- name: Check if database is already initialized
stat:
path: '/var/lib/pgsql/12/data/PG_VERSION'
register: init_status
- name: Initialize the slave database
shell: "pg_basebackup -D /var/lib/pgsql/12/data -h {{ master_host }} -X stream -c fast -U {{ repl_user }} -w -R"
when: init_status.stat.exists == False
- name: Start database
systemd:
state: started
name: postgresql-12
become_user: root
- name: Wait for postgres to listen on port 5432
wait_for:
port: 5432
delay: 2
- name: Configure recovery_target_timeline parameter
postgresql_set:
name: recovery_target_timeline
value: 'latest'
notify: Restart database
- name: Configure DBs to listen on ip address
postgresql_set:
name: listen_addresses
value: 'localhost,{{ ansible_ens3.ipv4.address }}'
notify: Restart database
Notes:
- On the task "pgpass for non interactive logins to the other node" you can see how you can loop over "groups" magic variable generating one line per host in .pgpass file.
- On step "Initialize the slave database" we are loading all the data from the beggining, connecting to the master database. This is not smart for large databases. You can use archiving instead, but we tried to keep a certain level of simplicity for this presentation.
Conclusion
The setup above assumes that applications can handle database connections (read/write, read only, load balancing, stale connections etc). In the future we may include a service that can handle connections transparently. But this is out of article's scope.
- Posted by Kostas Koutsogiannopoulos · Oct. 8, 2019

